This chapter is under active construction! You may be better off checking out other chapters in the meantime.
At a high level, this chapter aims to help readers build intuition about how long various model types and engines take to fit. Our first order of business, in Section 2.1, is demonstrating that fitting a model with tidymodels doesn’t take much longer than it would to fit the model without tidymodels’ unifying interface on top. That is, if I’d like to fit a boosted tree with XGBoost, will xgboost::xgb.train() fit notably more quickly than the analogous tidymodels interface boost_tree(engine = "xgboost")? Then, once you’re convinced the penalty in performance is negligible, we’ll move on to comparing fit times across modeling engines in Section 2.2. That is, does boost_tree(engine = "lightgbm") fit more quickly than boost_tree(engine = "xgboost")?
2.1 Tidymodels overhead
While the tidymodels team develops the infrastructure that users interact with directly, under the hood, we send calls out to other people’s modeling packages—or modeling engines—that provide the actual implementations that estimate parameters, generate predictions, etc. The process looks something like this:
A graphic representing the tidymodels interface. In order, step 1 “translate”, step 2 “call”, and step 3 “translate”, outline the process of translating from the standardized tidymodels interface to an engine’s specific interface, calling the modeling engine, and translating back to the standardized tidymodels interface. Step 1 and step 3 are in green, while step 2 is in orange.
When thinking about the time allotted to each of the three steps above, we refer to the “translate” steps in green as the tidymodels overhead. The time it takes to “translate” interfaces in steps 1) and 3) is within our control, while the time the modeling engine takes to do its thing in step 2) is not.
Let’s demonstrate with an example classification problem. Generating some data:
…we’d like to model the class using the remainder of the variables in this dataset using a logistic regression. We can using the following code to do so:
The default engine for a logistic regression in tidymodels is stats::glm(). So, in the style of the above graphic, this code:
Translates the tidymodels code, which is consistent across engines, to the format that is specific to the chosen engine. In this case, there’s not a whole lot to do: it passes the preprocessor as formula, the data as data, and picks a family of stats::binomial.
Calls stats::glm() and collects its output.
Translates the output of stats::glm() back into a standardized model fit object.
Again, we can control what happens in steps 1) and 3), but step 2) belongs to the stats package.
The time that steps 1) and 3) take is relatively independent of the dimensionality of the training data. That is, regardless of whether we train on one hundred or a million data points, our code (as in, the translation) takes about the same time to run. Regardless of training set size, our code pushes around small, relational data structures to determine how to correctly interface with a given engine. The time it takes to run step 2), though, depends almost completely on the size of the data. Depending on the modeling engine, modeling 10 times as much data could result in step 2) taking twice as long, or 10x as long, or 100x as long as the original fit.
So, while the absolute time allotted to steps 1) and 3) is fixed, the portion of total time to fit a model with tidymodels that is “overhead” depends on how quick the engine code itself is. How quick is a logistic regression with glm() on 100 data points?
bench::mark(fit =glm(class ~ ., family = binomial, data = d)) %>%select(expression, median)
# A tibble: 1 × 2
expression median
* <bch:expr> <bch:tm>
1 fit 2.28ms
Pretty dang fast. That means that, if the tidymodels overhead is one second, we’ve made this model fit a thousand times slower!
In practice, the overhead here has hovered around a millisecond or two for the last couple years, and machine learning practitioners usually fit much more computationally expensive models than a logistic regression on 100 data points. You’ll just have to believe me on that second point. Regarding the first:
bench::mark(parsnip =fit(logistic_reg(), class ~ ., d),stats =glm(class ~ ., family = binomial, data = d),check =FALSE)
Remember that the first expression calls the second one, so the increase in time from the second to the first is the “overhead.” In this case, it’s 0.858 milliseconds, or 26.9% of the total elapsed time.
So, to fit a boosted tree model on 1,000,000 data points, step 2) might take a few seconds. Steps 1) and 3) don’t care about the size of the data, so they still take a few thousandths of a second. No biggie—the overhead is negligible. Let’s quickly back that up by fitting boosted tree models on simulated datasets of varying sizes, once with the XGBoost interface and once with parsnip’s wrapper around it.
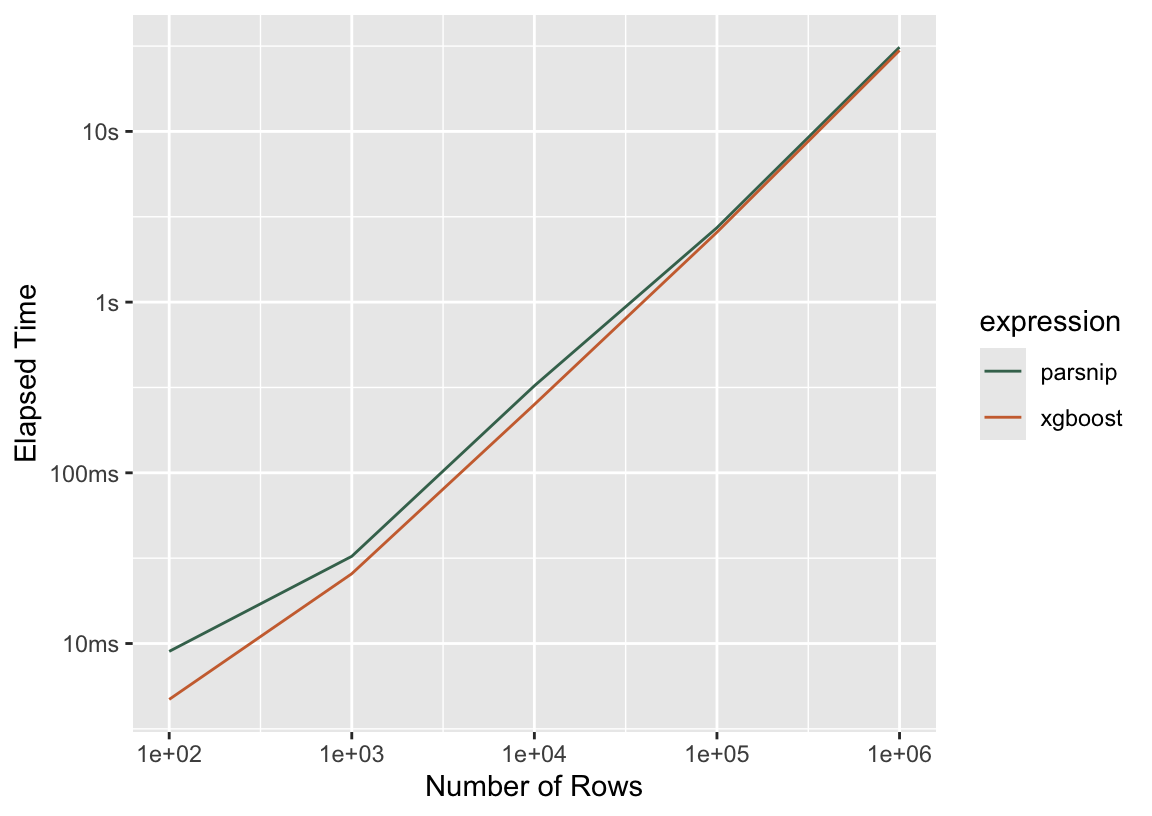
Elapsed fit times for XGBoost itself versus XBGoost interfaced with through parsnip. Fit times are non-negligigbly different only for very small data.
In the left-most model fits on 100 rows, the model fit with XGBoost itself takes 4.7 milliseconds while parsnip takes 8.99, a 91.1% increase in total elapsed time. However, that increase shrinks to 28.7% with an 1000-row dataset, and is fractions of a percent by the time there are hundreds of thousands of rows in the training data. This is the gist of tidymodels’ overhead for modeling engines: as dataset size and model complexity grow larger, the underlying model fit itself takes up increasingly large proportions of the total evaluation time.
Section 1.1.3 showed a number of ways users can cut down on the evaluation time of their tidymodels code. Making use of parallelism, reducing the total number of model fits needed to search a given grid, and carefully constructing that grid to search over are all major parts of the story. However, the rest of this chapter will focus explicitly on choosing performant modeling engines.
2.2 Benchmarks
The following is a shiny app based on experimental benchmarks. For a given selection of model configurations, the app displays the time to resample various model configurations across a given number of rows of training data.
#| '!! shinylive warning !!': |
#| shinylive does not work in self-contained HTML documents.
#| Please set `embed-resources: false` in your metadata.
#| label: models-app
#| embed-resources: false
#| standalone: true
#| viewerHeight: 600
#| eval: true
#| echo: false
library(ggplot2)
library(bench)
library(qs)
library(shiny)
library(bslib)
library(shinylive)
library(scales)
options(
ggplot2.discrete.colour = c(
"#1a162d", "#42725c", "#cd6f3d", "#a8ab71",
"#8b4b65", "#557088", "#d9b594", "#6b705c", "#956b4b", "#2d4041"
)
)
n_rows <- round(10^seq(from = 2, to = 6, by = .5))
reference_mark <- 37002
footer_context <- paste0(collapse = "", c(
"Timings estimate the time to evaluate an initial set of 10 models across 10 ",
"resamples, resulting in 100 model fits on 9/10th of rows, 100 sets of ",
"predictions on 1/10th of rows, and metric calculations on each set of predictions."
))
load(url("https://raw.githubusercontent.com/simonpcouch/emlwr/main/data/models/app/bm.rda"))
load(url("https://raw.githubusercontent.com/simonpcouch/emlwr/main/data/models/app/cpus.rda"))
# copying over r-lib/bench#144
bench_time_trans <- function(base = 10) {
if (is.null(base)) {
return(
scales::trans_new("bch:tm", as.numeric, as_bench_time,
breaks = scales::pretty_breaks(), domain = c(1e-100, Inf)
)
)
}
trans <- function(x) log(as.numeric(x), base)
inv <- function(x) bench::as_bench_time(base ^ as.numeric(x))
trans_new(paste0("bch:tm-", format(base)), trans, inv,
breaks = log_breaks(base = base), domain = c(1e-100, Inf))
}
ui <- page_fillable(
theme = bs_theme(
bg = "#ffffff",
fg = "#333333",
primary = "#42725c",
),
title = "Time To Tune",
layout_columns(
selectInput(
"model", "Model:",
choices = unique(bm$model),
multiple = TRUE,
selected = c(
"linear_reg (glmnet)",
"boost_tree (xgboost)",
"boost_tree (lightgbm)"
)
)
),
layout_sidebar(
sidebar = sidebar(
open = "always",
position = "right",
selectInput(
"task", "Task:",
choices = unique(bm$task),
selected = "regression"
),
# sliderInput(
# "n_workers", "Number of Workers:",
# value = 1,
# min = 1,
# max = 10,
# step = 1
# ),
# selectInput(
# "tuning_fn", "Tuning Function:",
# choices = unique(bm$tuning_fn)
# ),
selectInput(
"cpu", "CPU:",
choices = NULL
),
markdown("Timings scaled according to [CPU benchmarks](https://www.cpubenchmark.net/cpu_list.php).")
),
card(
full_screen = TRUE,
card_header("Time To Tune"),
plotOutput("plot"),
footer = footer_context
)
)
)
server <- function(input, output, session) {
updateSelectizeInput(
session,
'cpu',
choices = cpus$name,
server = TRUE,
selected = "Intel Core i7-13700"
)
output$plot <- renderPlot({
new_data <- bm[
bm$model %in% input$model &
bm$task == input$task &
bm$n_workers == 1 &
bm$tuning_fn == "tune_grid",
]
if (!identical(input$cpu, "")) {
new_data$time_to_tune_float <-
new_data$time_to_tune_float *
(reference_mark / cpus$mark[cpus$name == input$cpu])
new_data$time_to_tune <- as_bench_time(new_data$time_to_tune_float)
}
ggplot(new_data, aes(x = n_rows, y = time_to_tune, col = model, group = model)) +
geom_point() +
geom_line() +
scale_x_log10(labels = comma) +
scale_y_continuous(trans = bench_time_trans(base = 10)) +
labs(x = "Number of Rows", y = "Time to Tune (seconds)", col = "Model") +
theme(
legend.position = "bottom"
)
})
}
app <- shinyApp(ui, server)
app
This app allows for quickly juxtaposing the time that it might take to evaluate performance across various modeling approaches. In Section 2.2.1, I’ll go into a bit more detail about what each data point in this app represents and why, and then analyze the data in further detail in Section 2.2.3.
2.2.1 One data point
When the app first starts, the left-most point labeled boost_tree (lightgbm) is the observed time to sequentially evaluate an initial set of 10 models across 10 cross-validation folds of an 1000 row training set, resulting in 100 model fits on 900 rows, 100 sets of predictions of 100 rows, and metric calculations on each set of predictions. The actual benchmarking code is a bit more involved, but the code underlying that single data point looks something like the following.
First, we load core packages as well as the bonsai parsnip extension (for lightgbm support):
library(tidymodels)library(bonsai)
Next, we’ll simulate a dataset with 1000 rows using simulate_regression(), Efficient Machine Learning with R’s in-house simulation function:
Now, we specify a boosted tree model specification using the LightGBM engine. In this experiment, any tunable parameter (defined by whether tidymodels has a parameter definition that automatically kicks in when generating grids) is set to be tuned.
Each of these model fits are carried out with minimal preprocessors based on Tidy Modeling with R’s “Recommended Preprocessing” appendix (Max Kuhn and Silge 2022). In this case, Kuhn and Silge recommend that users impute missing values for both numeric predictors (we do so using the median for all) and categorical predictors (we do so using the mode) when working with boosted trees.
With our data resampled and a modeling workflow defined, we’re ready to resample this model. The resampling process will propose 10 different possible sets of parameter values for each parameter tagged with tune(). This will happen automatically under the hood of tune_grid(), but we can replicate this ourselves using dials:
The point in the above plot is the time that those 100 model fits took altogether; in other words, the time that we’d wait for tune_grid() to evaluate.
The data underlying this app is generated from thousands of experiments that look just like the one above, but varying the structure of the training data, the numbers of rows in the training data and the number of CPU cores utilized. In all, 585 such experiments form the underlying data for this app:
This seems a bit involved for the purposes of getting a rough sense of how long a given model may take to fit; why don’t we just use default parameter values from tidymodels and pass the model specification straight to fit()?
There are a few reasons for this. In general, though, resampling a model specification across an initial set of possible parameter values is a fundamental unit of interactive machine learning. This initial resampling process gives the practitioner a sense for the ballpark of predictive performance she can expect for a given model task and how various parameter values may affect that performance. Does a higher learn_rate result in better predictive performance? How many trees is enough? A single model fit leaves the answer to all of these questions unknown.
Importantly, too, the time that a given model specification takes to fit can vary greatly depending on parameter values. For example, only exploring the time to fit() rather than resample across a set of values would obscure the difference in these two elapsed times:
By summing across many model configurations that result in varied fit times, we can get a better sense for a typical time to fit across typical parameter values.
2.2.3 Analysis
2.2.3.1 Decision Trees
Decision trees recursively partition data by selecting values of predictor variables that, when split at that value, best predict the outcome at each node. The tree makes predictions by routing new samples through these splits to reach leaf nodes containing similar training examples. The tidymodels framework supports a number of modeling engines for fitting and predicting from decision trees, including C5.0, partykit, rpart, and spark, and decision trees can be used for either classification or regression (with some engine-specific exceptions).
At the highest level, here’s what the tuning times for various decision_tree() engines supported by tidymodels look like:
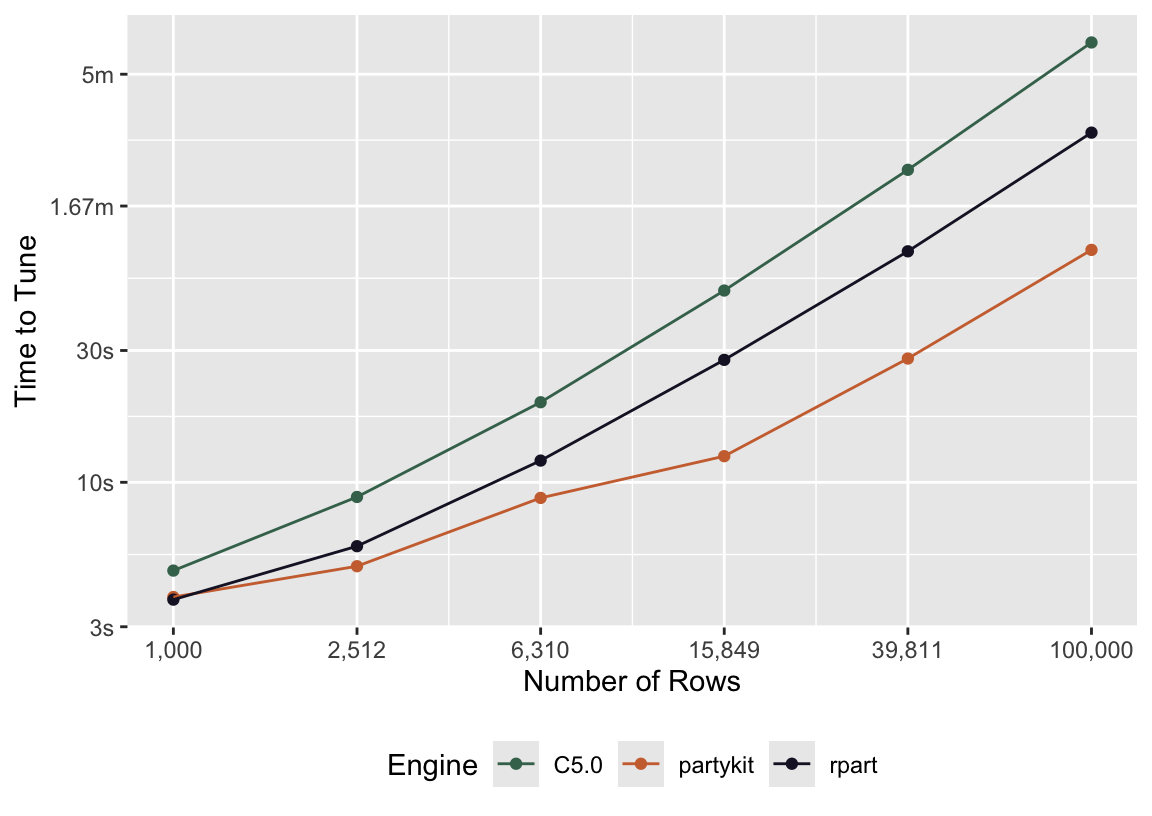
Figure 2.1: Elapsed times to generate preliminary tuning results for decision trees with tidymodels by modeling engine.
Figure 2.1 is a special case of the Time to Tune app from Section 2.2; each data point shows the total time to fit and predict from 100 decision trees of varying parameterizations. partykit consistently evaluates the fastest across all dataset sizes, while C5.0 is the slowest, with the performance gap between engines widening as the number of rows increases.
tidymodels supports tuning the decision tree hyperparameters min_n, tree_depth, and cost_complexity.1 We’ll discuss the implications for each on the time to fit decision trees in the rest of this section. In general, though, it’s helpful to keep in mind that the computationally intensive part of fitting decision trees is the search for optimal split points. Because of this, more complex trees generally take longer to fit than less complex trees, and parameter values allowing for more complex trees will tend to result in longer fit times. That said, the effect on fit time of changing individual parameter values is often relatively mild, as changes in one parameter value are mediated by other parameters.
First, the Minimum Points Per Node, or min_n, is the minimum number of training set observations in a node required for the node to be split further. For example, if only 3 observations meet some split criteria some_variable < 2 and min_n is set to 3, then the tree will make a prediction at that node rather than considering whether to further break those 3 observations up into smaller buckets based on another split criteria before making predictions. Smaller values of min_n allow for more complex trees, and thus the time to fit a decision tree is inversely correlated to min_n when the complexity of the tree isn’t mediated by other parameter values. In CART-based settings like with engine = "rpart", min_n can usually be set to a reasonably high value without affecting predictive performance “since smaller nodes are almost always pruned away by cross-validation”; in other words, even if the tree is allowed to generate more splits via a small min_n value, those splits based on smaller numbers of observations are often pruned away via the cost_complexity parameter anyway (Therneau and Atkinson 2025).
Let’s see how this plays out in practice:
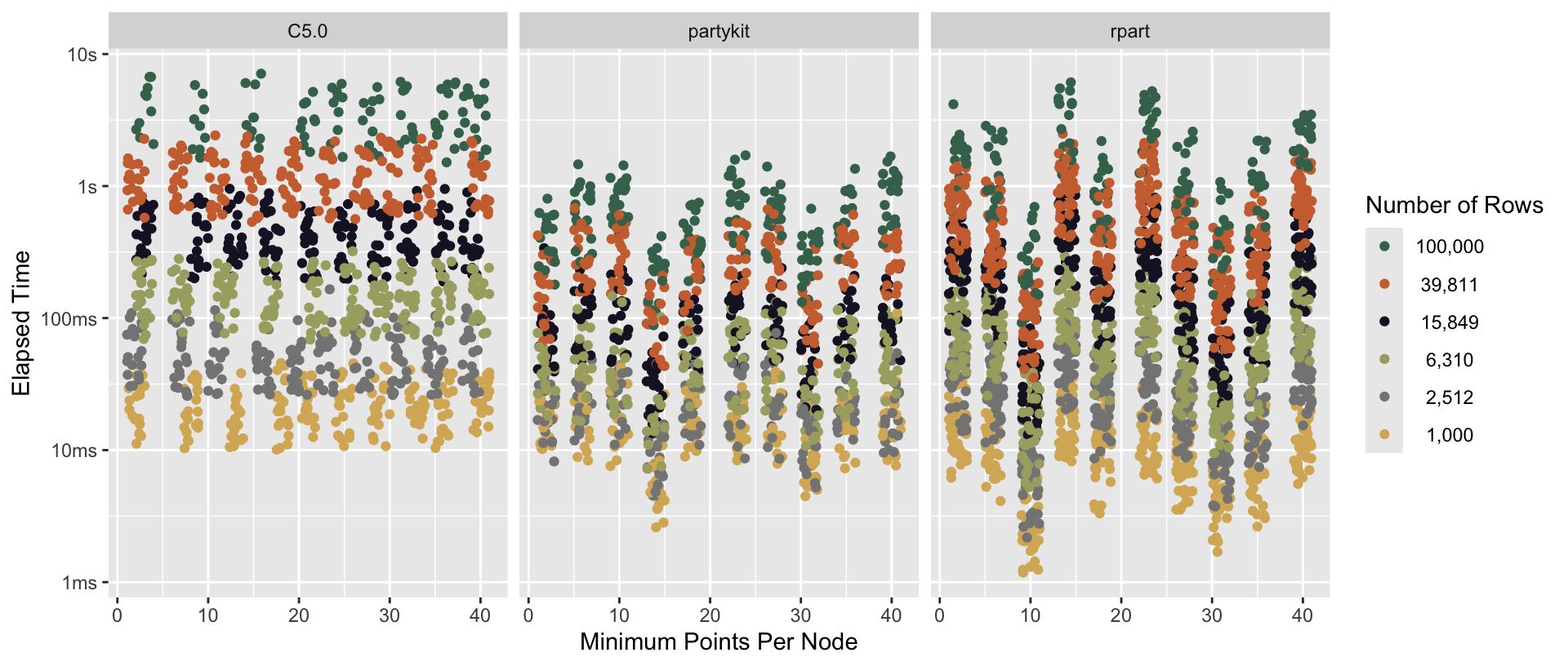
Figure 2.2: Distributions of time-to-fit for various minimum points per node values, faceted by engine and colored according to numbers of rows. Generally, in practice, the minimum points per node doesn’t tend to affect fit times as tree complexity is mediated by other parameter values.
This plot disaggregates the information in Figure 2.1. Instead of summing across the time to fit and predict from each model to determine a data point (with varying values of min_n and other parameters), this plot shows one point per model fit. Generally, we see that min_n has little effect on the time to fit across all modeling engines supported by tidymodels.
The Tree Depth, or tree_depth in tidymodels, is the maximum depth of the tree. For example, if tree_depth = 2, the tree must reach a node (i.e. a point at which a prediction is made rather than a further split) after splitting twice. Larger values of tree_depth allow for more complex trees, and thus the time to fit a decision tree increases as tree_depth does unless the complexity of the tree is mediated by some other parameter.
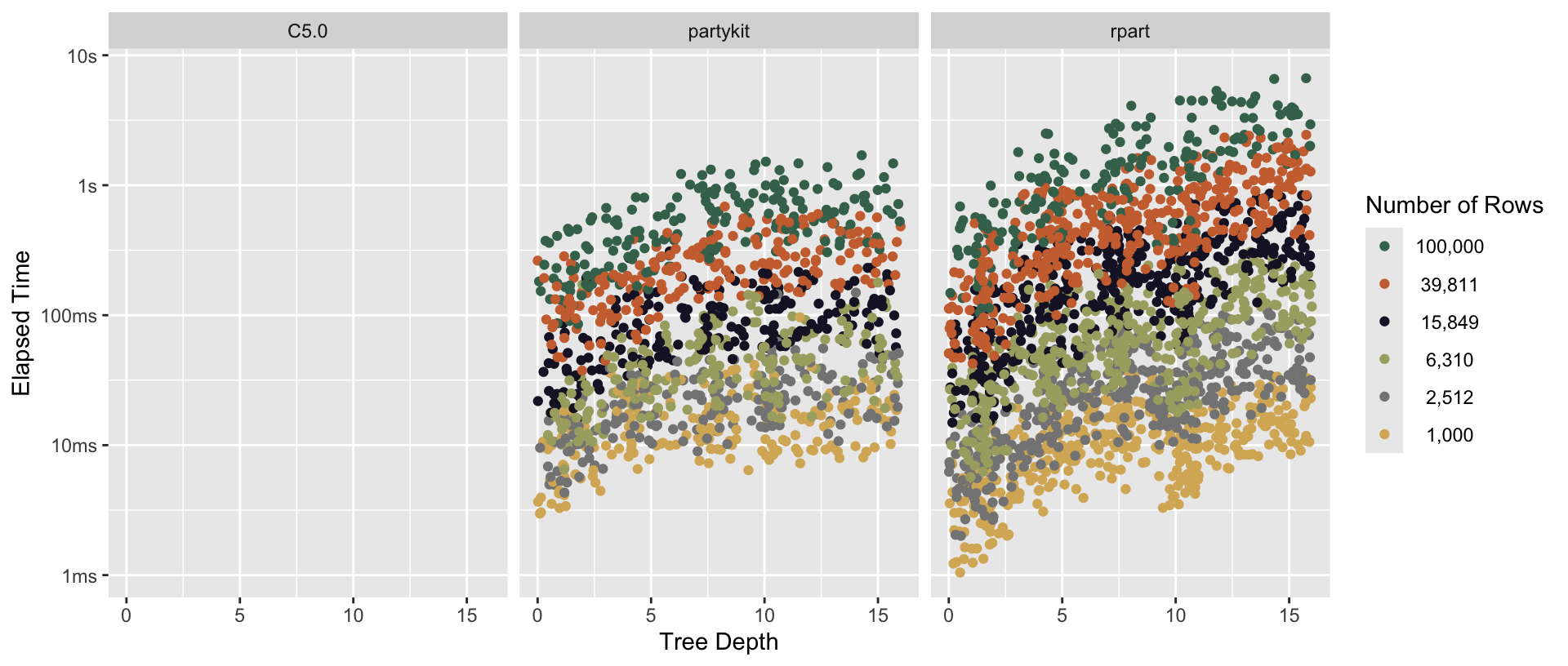
Figure 2.3: Distributions of time-to-fit for various tree depth values, faceted by engine and colored according to numbers of rows. For the engines that support tree depth, higher values of tree depth tend to result in greater fit times, even as other parameter values vary. C5.O doesn’t support the tree depth parameter (Max Kuhn and Quinlan 2023; Quinlan 2014).
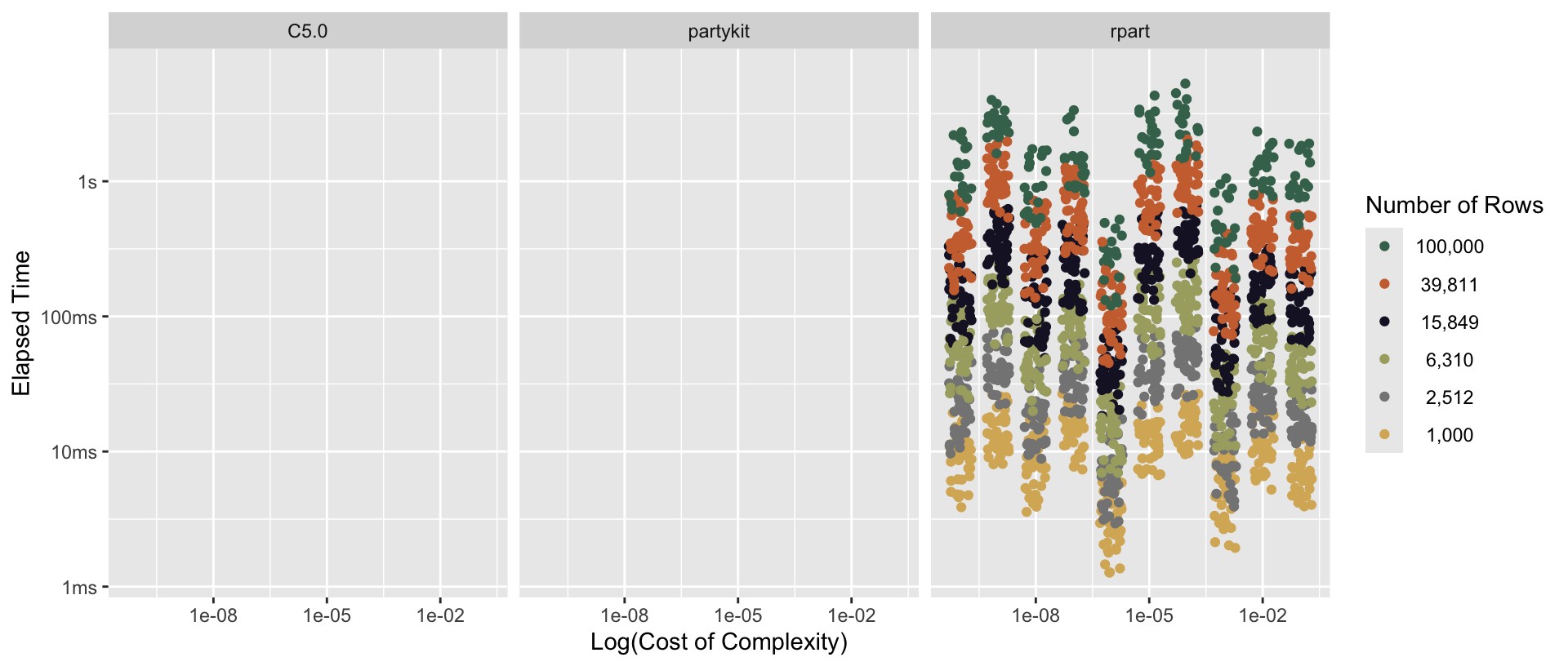
The Cost of Complexity, or cost_complexity in tidymodels, is a penalization parameter (often referred to as \(C_p\)) on adding additional complexity to the tree. This parameter is only used by CART models, so is available only for specific engines. When training CART-based decision trees, once splits are generated, each are evaluated according to how much they decrease error on out-of-sample data relative to the tree without that split. If the decrease in error doesn’t surpass some threshold \(C_p\), the split is “pruned” back, forming a less complex tree. Higher values of penalization mean that the decision tree will evaluate (and thus search for) fewer splits in total, ultimately saving “considerable computational effort” and decreasing the time to fit the model (Therneau and Atkinson 2025; M. Kuhn 2013).
Figure 2.4: Distributions of time-to-fit for various values of cost of complexity, faceted by engine and colored according to numbers of rows. Neither C5.0 nor partykit make use of this parameter (Quinlan 2014; Hothorn, Hornik, and Zeileis 2006).
Note
C5.0 and partykit make use of related parameters to automatically prune trees, though they aren’t supported by tidymodels as a default tuning parameter as they’re engine-specific. C5.0’s confidence factor parameter is a very computationally efficient way to control complexity, though do note that the approach stands on “shaky statistical grounds” (M. Kuhn 2013). partykit determines whether a split is “worth it” based on hypothesis testing, and the significance level of that hypothesis test can be used to prune splits more aggressively (Hothorn, Hornik, and Zeileis 2006).
Again, the time-consuming portion of fitting decision trees is searching for optimal predictor values to split on. Because of this, more complex trees tend to take longer to fit than less complex trees. On its own, though, this doesn’t necessarily mean that setting an individual parameter value to allow for a more complex tree will result in a longer fit time, and we saw this effect above. Instead, the complex interplay of many parameter values simultaneously allowing for greater complexity is what drives longer fit times. We can quickly demonstrate this in-the-small with a brief set of model fits.
# generate a dataset with 100,000 rowsset.seed(1)d <-simulate_classification(100000)# define a decision tree model specificationspec_small <-decision_tree(cost_complexity = .1, tree_depth =2, min_n =1000) %>%set_engine("rpart") %>%set_mode("classification")
In the above, spec_small defines a very minimal tree; this cost_complexity() value heavily penalizes further splits, the tree_depth describes a very shallow tree, and min_n only allows for further splits when a given split contains many observations.
Now, we can examine the effect of setting individual values on fit time by benchmarking the time to fit a simple tree by all measures, then toggling each of the parameter values individually to allow for more complex trees, and finally by toggling all of them to allow for a very complex tree.
bench::mark(# small by all measuressmall =fit(object = spec_small, formula = class ~ ., data = d),# allowing for greater complexity with only one parameter valuecomplex_cost_complexity =fit(set_args(spec_small, cost_complexity =10e-9), class ~ ., d ),complex_tree_depth =fit(set_args(spec_small, tree_depth =30), class ~ ., d ),complex_min_n =fit(set_args(spec_small, min_n =1), class ~ ., d ),# allowing for greater complexity with all parameter valuescomplex =fit(set_args(spec_small, cost_complexity =10e-9, tree_depth =30, min_n =1), class ~ ., d ),check =FALSE)
Again, we see that individual parameter values allowing for greater complexity are mediated by other parameter values, but setting them all together allows for a complex tree and, thus, a significantly longer fit time.
Summary: Decision Trees
More complex decision trees take longer to fit.
Setting individual parameter values to allow for more complex fits doesn’t necessarily mean that a tree will take longer to fit.
Compared to many of the other methods described in this chapter, decision trees are quite quick-fitting.
Hothorn, Torsten, Kurt Hornik, and Achim Zeileis. 2006. “Unbiased Recursive Partitioning: A Conditional Inference Framework.”Journal of Computational and Graphical Statistics 15 (3): 651–74. https://doi.org/10.1198/106186006X133933.
Kuhn, M. 2013. “Applied Predictive Modeling.” Springer.
That is, tidymodels provides default distributions of parameter values to sample from for these parameters. Other parameters can be tuned by providing your own distributions using the dials package.↩︎